00:06 Today we'll start looking into AsyncSequence. This works like a
normal Sequence, except elements are returned asynchronously. By writing
AsyncSequences, we can create abstractions of work normally done with streams
and callbacks.
00:39 To familiarize ourselves with the concept, we want to see how we
can read a large file without a spike in memory usage. For this, we've
downloaded a Wikipedia dump in the form of compressed XML. In theory, we should
be able to use AsyncSequence to read bytes or chunks of bytes instead of
having to load the entire file at once.
01:27 By writing multiple AsyncSequences, we can create separate,
composable abstractions of the different operations we need, i.e. reading in
chunks of data, decompressing data, and parsing XML.
Synchronous Versus Asynchronous
01:49 We won't do this all at once. We start by reading a plain,
uncompressed XML file and counting the number of lines. Let's first do so
without using AsyncSequence, but instead by loading the entire file into
memory. We do use an abstraction, enumerateLines, because splitting the string
on newline characters would take too much time:
func sample() async throws {
let start = Date.now
let url = Bundle.main.url(forResource: "enwik8", withExtension: "xml")!
let str = try String(contentsOf: url)
var counter = 0
str.enumerateLines { _, _ in
counter += 1
}
print(counter)
print("Duration: \(Date.now.timeIntervalSince(start))")
}
03:37 It takes a little longer than a second to load 1.1 million lines.
Xcode's memory graph tells us the memory usage has a spike of 300 MB. This is
typically what we'd expect for this kind of technique: all 100 MB of the source
file — and sometimes even much more — need to be kept in memory.
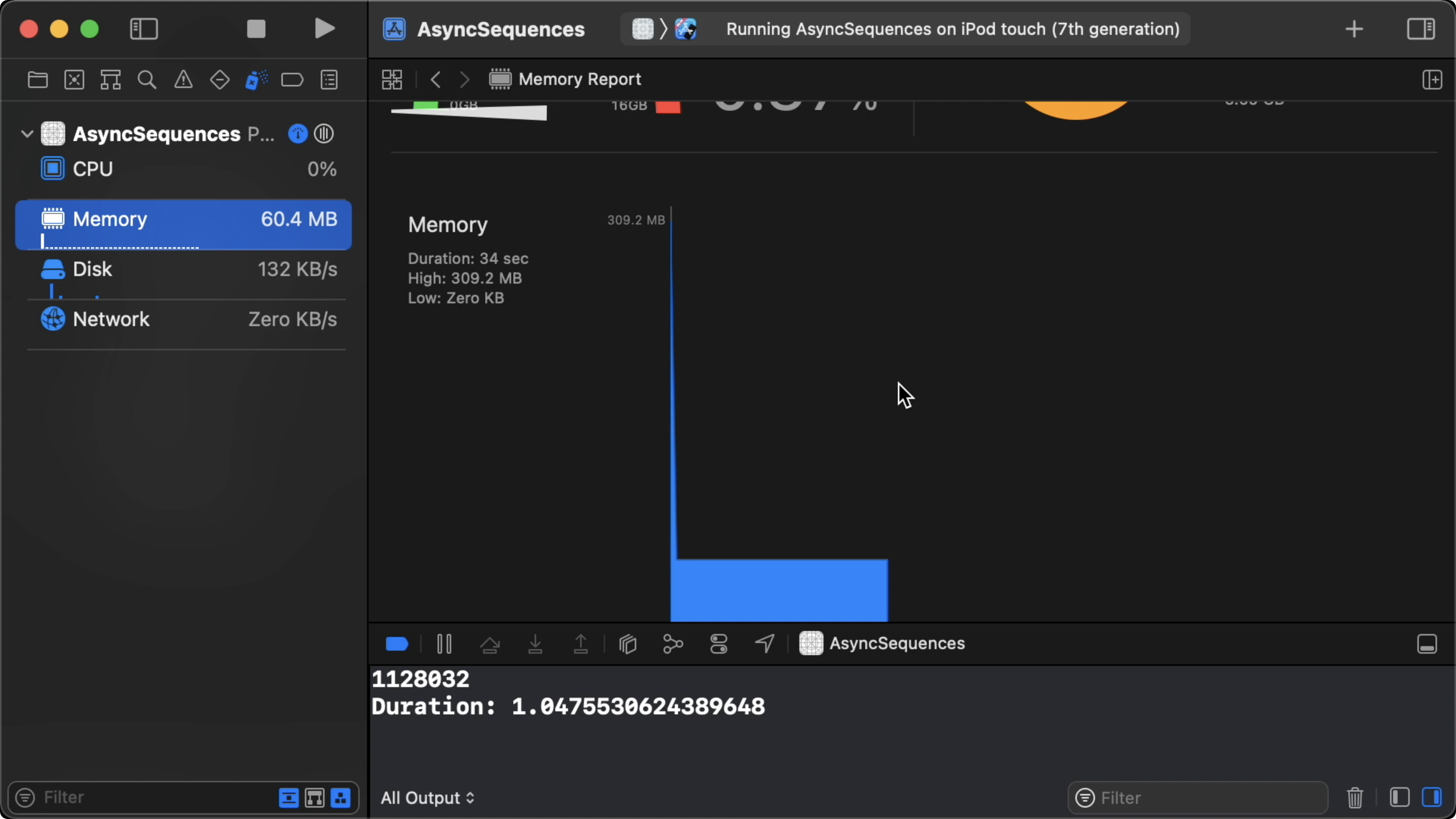
04:47 Now, let's count the lines of the file asynchronously:
func sample() async throws {
let start = Date.now
let url = Bundle.main.url(forResource: "enwik8", withExtension: "xml")!
var counter = 0
let fileHandle = try FileHandle(forReadingFrom: url)
for try await _ in fileHandle.bytes.lines {
counter += 1
}
print(counter)
print("Duration: \(Date.now.timeIntervalSince(start))")
}
05:33 This runs in half the amount of time, and it uses constant memory.
The peak is 60 MB, which means the XML file is never held in memory in its
entirety:
06:20 We have to use try await in the loop because fileHandle.bytes
returns an AsyncSequence of single bytes (UInt8). The appended .lines call
converts this sequence into a sequence of lines by iterating over the bytes,
doing some Unicode processing, and chunking the bytes between line breaks.
07:22 As we ask for more lines, the lines sequence asks the bytes
sequence for more bytes, and the bytes sequence asks the file handle to read
some more data. Because this happens in chunks, the memory usage stays constant.
If we'd do the same with a larger file, it would take longer, but the memory
usage would stay the same.
07:48 In other words, iterating over the lines drives the reading of
chunks of the file. This was all possible before, but it was much more difficult
to do before async/await.
Compressed Data
08:30 Next, we want to asynchronously count the lines of a compressed
file. For this, we have another file containing the same data compressed using
the zlib algorithm. And, we wrote a wrapper around the Compression framework. We
don't want to waste time discussing how this wrapper works; all we need to know
is we can feed it chunks of compressed data, and it returns the data
decompressed (or vice versa).
09:23 The Compressor expects chunks of a certain size, so we first
have to write an AsyncSequence for chunking the data, and later we have to
write one for decompressing the chunks.
Chunking Data
09:48 We create a new AsyncSequence, called Chunked, which takes in
a base sequence of bytes — i.e. UInt8 — and a chunk size. For now, we default
this chunk size to the buffer size of our Compressor wrapper. To conform this
to AsyncSequence, we need to create an AsyncIterator:
struct Chunked<Base: AsyncSequence>: AsyncSequence where Base.Element == UInt8 {
var base: Base
var chunkSize: Int = Compressor.bufferSize typealias Element = Data
struct AsyncIterator: AsyncIteratorProtocol {
var base: Base.AsyncIterator
var chunkSize: Int
mutating func next() async throws -> Data? {
}
}
func makeAsyncIterator() -> AsyncIterator {
AsyncIterator(base: base.makeAsyncIterator(), chunkSize: chunkSize)
}
}
11:58 We can already see how much AsyncSequence and Sequence have in
common. Their APIs are basically the same, apart from the Async prefixes in
the protocol names and the iterator's next method being async.
12:22 The actual work of Chunked is done inside the next method.
Here, we need to call the base sequence's iterator and collect the returned
bytes in a Data value until its count matches chunkSize:
struct Chunked<Base: AsyncSequence>: AsyncSequence where Base.Element == UInt8 {
var base: Base
var chunkSize: Int = Compressor.bufferSize typealias Element = Data
struct AsyncIterator: AsyncIteratorProtocol {
var base: Base.AsyncIterator
var chunkSize: Int
mutating func next() async throws -> Data? {
var result = Data()
while let element = try await base.next() {
result.append(element)
if result.count == chunkSize { return result }
}
}
}
func makeAsyncIterator() -> AsyncIterator {
AsyncIterator(base: base.makeAsyncIterator(), chunkSize: chunkSize)
}
}
13:18 We get out of the while loop either if the base iterator returns
nil immediately, or if it returns nil after returning a number of bytes but
before we complete a chunk. If the base iterator hasn't returned any bytes, we
need to return nil to signal the end of the sequence. Otherwise, we return the
Data we've collected:
struct Chunked<Base: AsyncSequence>: AsyncSequence where Base.Element == UInt8 {
var base: Base
var chunkSize: Int = Compressor.bufferSize typealias Element = Data
struct AsyncIterator: AsyncIteratorProtocol {
var base: Base.AsyncIterator
var chunkSize: Int
mutating func next() async throws -> Data? {
var result = Data()
while let element = try await base.next() {
result.append(element)
if result.count == chunkSize { return result }
}
return result.isEmpty ? nil : result
}
}
func makeAsyncIterator() -> AsyncIterator {
AsyncIterator(base: base.makeAsyncIterator(), chunkSize: chunkSize)
}
}
14:25 In an extension of AsyncSequence with an element type of
UInt8, we write a helper to convert the sequence into a Chunked:
extension AsyncSequence where Element == UInt8 {
var chunked: Chunked<Self> {
Chunked(base: self)
}
}
14:48 Now we can use fileHandle.bytes.chunked to read chunks of data
from a file:
func sample() async throws {
let start = Date.now
let url = Bundle.main.url(forResource: "enwik8", withExtension: "zlib")!
var counter = 0
let fileHandle = try FileHandle(forReadingFrom: url)
for try await chunk in fileHandle.bytes.chunked {
print(chunk)
counter += 1
}
print(counter)
print("Duration: \(Date.now.timeIntervalSince(start))")
}
15:04 In the console, we can see that all chunks have the same size,
except for the last one, which is smaller because it's the remainder of the
file's bytes.
15:26 We also see that it takes almost five seconds to read all 3,052
chunks. Clearly, this code is very inefficient. The fileHandle.bytes sequence
already reads chunks of a file and returns them as individual bytes, which we
subsequently collect to recreate chunks. It'd be much more efficient to read the
chunks directly from the file handle, but that's not the point of this episode.
Decompressing Data Chunks
15:54 We have chunks of zlib-compressed data, and now we want to
decompress these chunks. So, we'll write another AsyncSequence, and this time,
it takes a base sequence of Data and it uses an Compressor instance,
configured to either compress or decompress data:
struct Compressed<Base: AsyncSequence>: AsyncSequence where Base.Element == Data {
var base: Base
var method: Compressor.Method
typealias Element = Data
struct AsyncIterator: AsyncIteratorProtocol {
var base: Base.AsyncIterator
var compressor: Compressor
mutating func next() async throws -> Data? {
}
}
func makeAsyncIterator() -> AsyncIterator {
let c = Compressor(method: method)
return AsyncIterator(base: base.makeAsyncIterator(), compressor: c)
}
}
18:44 In the next method, we assume the data chunk size matches up
with the compressor's chunk size. If we can receive a chunk from the base
sequence, we pass it to the compressor and return the result. If we receive
nil, we've reached the end of the base sequence. In that case, we check if the
compressor's buffer contains any leftover data. If it does, we return it. If it
doesn't, we return nil to signal the end of the sequence:
struct Compressed<Base: AsyncSequence>: AsyncSequence where Base.Element == Data {
var base: Base
var method: Compressor.Method
typealias Element = Data
struct AsyncIterator: AsyncIteratorProtocol {
var base: Base.AsyncIterator
var compressor: Compressor
mutating func next() async throws -> Data? {
if let chunk = try await base.next() {
return try compressor.compress(chunk)
} else {
let result = try compressor.eof()
return result.isEmpty ? nil : result
}
}
}
func makeAsyncIterator() -> AsyncIterator {
let c = Compressor(method: method)
return AsyncIterator(base: base.makeAsyncIterator(), compressor: c)
}
}
21:10 Like before, we write an extension with a helper to create a
Compressed sequence out of a Data sequence:
extension AsyncSequence where Element == Data {
var decompressed: Compressed<Self> {
Compressed(base: self, method: .decompress)
}
}
21:48 Now we can append .decompressed to our chunked data sequence,
and then we process the compressed file:
func sample() async throws {
let start = Date.now
let url = Bundle.main.url(forResource: "enwik8", withExtension: "zlib")!
var counter = 0
let fileHandle = try FileHandle(forReadingFrom: url)
for try await chunk in fileHandle.bytes.chunked.decompressed {
print(chunk)
counter += 1
}
print(counter)
print("Duration: \(Date.now.timeIntervalSince(start))")
}
22:21 We read around 1,100 chunks of decompressed data. We can decode
these chunks into strings to see that the data is being decompressed correctly,
even if some strings are logically broken due to the data being chopped in the
wrong places:
func sample() async throws {
let start = Date.now
let url = Bundle.main.url(forResource: "enwik8", withExtension: "zlib")!
var counter = 0
let fileHandle = try FileHandle(forReadingFrom: url)
for try await chunk in fileHandle.bytes.chunked.decompressed {
print(String(decoding: chunk, as: UTF8.self))
counter += 1
}
print(counter)
print("Duration: \(Date.now.timeIntervalSince(start))")
}
23:14 decompressed gives us an AsyncSequence of Data. In the next
episode, we can create another sequence, flatten, to combine the chunks back
into bytes. After that, it should be easy to read lines or to parse the XML
data.
