00:06 We've already been exploring Swift's async/await APIs, mainly
focused on @MainActor and the bridging between a delegate receiving callbacks
from URLSession and the world of structured concurrency. But we haven't yet
looked at task groups, which make up the structured part of structured
concurrency.
00:54 With traditional tools like Grand Central Dispatch, we're used to
kicking off a job on some queue and hoping for the best. Working with structured
concurrency on the other hand — where a task will wait for all its child tasks
to finish before continuing — takes a very different mental model.
01:25 We're going to play with tasks by building a simple web crawler.
We'll crawl our own site, running locally to avoid accidentally overloading our
actual server, by fetching the first page's title and its outgoing links, and
then adding these links to a queue to be processed. We'll repeat this process
until we've crawled every page of our site.
We'll start by setting up the basic infrastructure today. Later, we'll look at
how to parallelize the crawler's work.
Crawler
02:01 We create a Crawler object, and we'll make it an
ObservableObject so we can use it with SwiftUI. The crawler exposes the pages
it fetched, along with their URLs, through its state property. Each Page
value holds a URL, a page title, and an array of outgoing links:
@MainActor
final class Crawler: ObservableObject {
@Published var state: [URL: Page] = [:]
func crawl(url: URL) async {
}
}
struct Page {
var url: URL
var title: String
var outgoingLinks: [URL]
}
02:47 The crawl method is async so that we can make it return when the
entire site is crawled.
Fetching a Page
03:04 But let's start with fetching a single page. In an extension of
URLSession, we write a helper method that loads data from the given URL and
returns a Page. We use XMLDocument to parse the data and to query the HTML
document for its title and links:
@MainActor
final class Crawler: ObservableObject {
@Published var state: [URL: Page] = [:]
func crawl(url: URL) async throws {
state[url] = try await URLSession.shared.page(from: url)
}
}
extension URLSession {
func page(from url: URL) async throws -> Page {
let (data, _) = try await data(from: url)
let doc = try XMLDocument(data: data, options: .documentTidyHTML)
let title = try doc.nodes(forXPath: "//title").first?.stringValue
}
}
05:16 By specifying "//title" as the path, we query all <title>
elements anywhere in the document. The stringValue of the first result should
give us the page title.
05:54 For the outgoing links, we query all <a> elements that have an
href attribute. We compactMap over the found nodes to mold them into the
URL values. For this, we filter out the nil values, and we check that a
valid URL can be created from the link. Also, a link may be relative, e.g.
/books, so we use the URL initializer that stores the page's URL as the base
URL:
extension URLSession {
func page(from url: URL) async throws -> Page {
let (data, _) = try await data(from: url)
let doc = try XMLDocument(data: data, options: .documentTidyHTML)
let title = try doc.nodes(forXPath: "//title").first?.stringValue
let links: [URL] = try doc.nodes(forXPath: "//a[@href]").compactMap { node in
guard let el = node as? XMLElement else { return nil }
guard let href = el.attribute(forName: "href")?.stringValue else { return nil }
return URL(string: href, relativeTo: url)
}
}
}
08:39 We now have all the ingredients needed to construct a Page:
extension URLSession {
func page(from url: URL) async throws -> Page {
let (data, _) = try await data(from: url)
let doc = try XMLDocument(data: data, options: .documentTidyHTML)
let title = try doc.nodes(forXPath: "//title").first?.stringValue
let links: [URL] = try doc.nodes(forXPath: "//a[@href]").compactMap { node in
guard let el = node as? XMLElement else { return nil }
guard let href = el.attribute(forName: "href")?.stringValue else { return nil }
return URL(string: href, relativeTo: url)
}
return Page(url: url, title: title ?? "", outgoingLinks: links)
}
}
Displaying Crawled Pages
09:07 In ContentView, we show a list of the crawled pages, sorted by
their URLs, and we call crawl in a task attached to the view:
struct ContentView: View {
@StateObject var crawler = Crawler()
var body: some View {
List {
ForEach(Array(crawler.state.keys.sorted(by: { $0.absoluteString < $1.absoluteString })), id: \.self) { url in
HStack {
Text(url.absoluteString)
Text(crawler.state[url]!.title)
}
}
}
.padding()
.frame(maxWidth: .infinity, maxHeight: .infinity)
.task {
do {
try await crawler.crawl(url: URL(string: "http://localhost:8000/")!)
} catch {
print(error)
}
}
}
}
12:27 We need to update our app's settings to allow outgoing
connections. Otherwise, every network request would result in a failure:
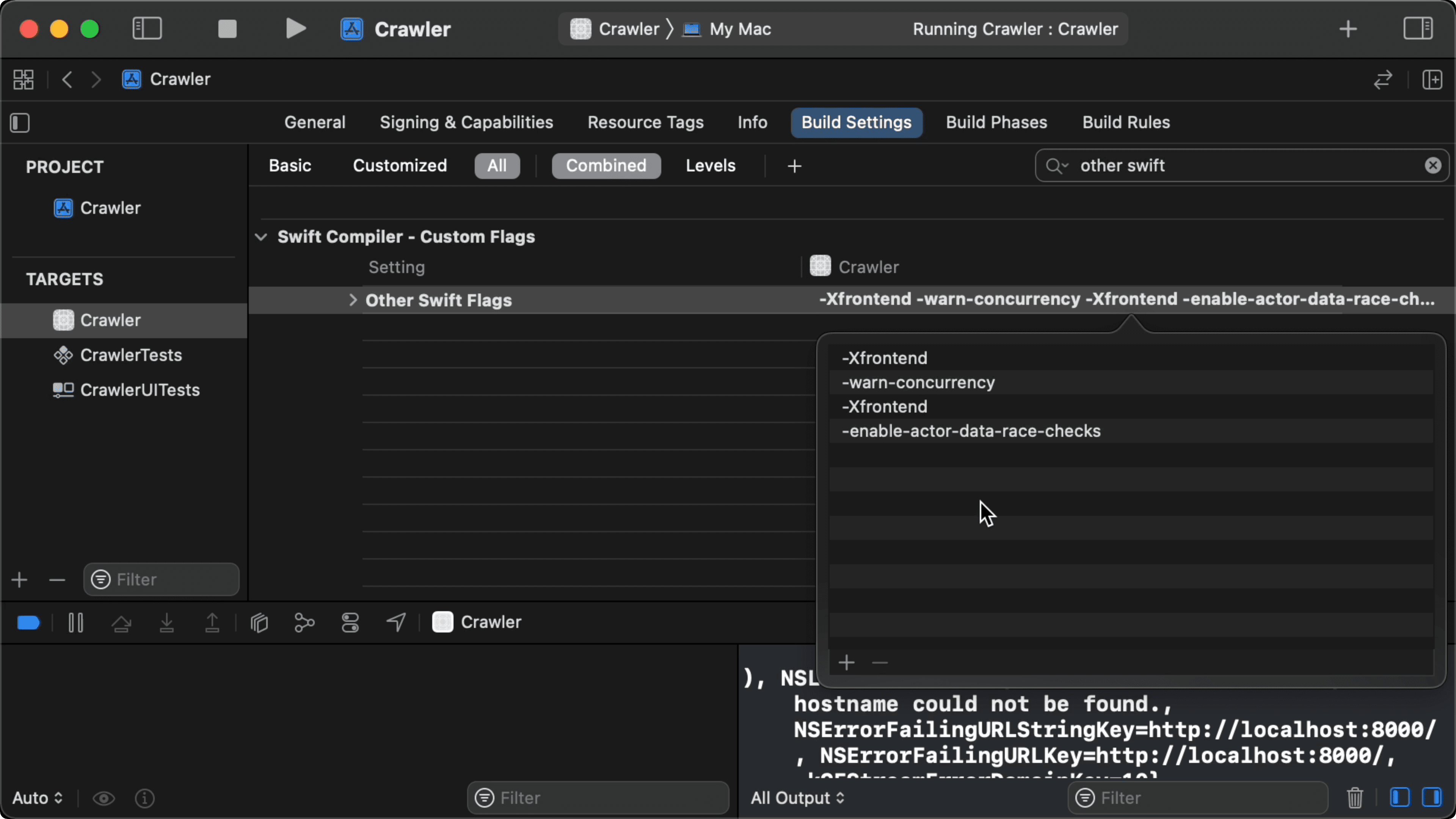
12:38 We also add the following compiler flags to the "Other Swift
Flags" field of the build settings to opt into compiler warnings about
concurrency:
-Xfrontend -warn-concurrency -Xfrontend -enable-actor-data-race-checks
13:10 This triggers a warning about ContentView being non-sendable. In
other words: it isn't safe to be captured by the task closure, which is what
we're implicitly doing by referencing the crawler property. We work around
this issue by adding the crawler object to the closure's capture list:
struct ContentView: View {
@StateObject var crawler = Crawler()
var body: some View {
List {
ForEach(Array(crawler.state.keys.sorted(by: { $0.absoluteString < $1.absoluteString })), id: \.self) { url in
HStack {
Text(url.absoluteString)
Text(crawler.state[url]!.title)
}
}
}
.padding()
.frame(maxWidth: .infinity, maxHeight: .infinity)
.task { [crawler] in
do {
try await crawler.crawl(url: URL(string: "http://localhost:8000/")!)
} catch {
print(error)
}
}
}
}
13:54 When we run the app, the first page is fetched. Next, we need to
take the local URLs from the page's outgoing links and add these to the crawling
queue. The processing of this queue is what we want to parallelize in the end,
but we'll crawl one page at a time at first.
Crawling Queue
14:44 We create a Set<URL> for the queue, and we start with the
requested URL as its only element. In a loop, we take the first URL from the
queue and load its page:
@MainActor
final class Crawler: ObservableObject {
@Published var state: [URL: Page] = [:]
func crawl(url: URL) async throws {
var queue: Set<URL> = [url]
while let job = queue.popFirst() {
state[job] = try await URLSession.shared.page(from: job)
}
}
}
16:11 Then, we filter the page's outgoing links so that we only have
"local" URLs — i.e. the ones that start with the URL we're crawling. We also
discard any URLs we've already seen. The remaining URLs are then added to the
queue:
@MainActor
final class Crawler: ObservableObject {
@Published var state: [URL: Page] = [:]
func crawl(url: URL) async throws {
let basePrefix = url.absoluteString
var queue: Set<URL> = [url]
while let job = queue.popFirst() {
let page = try await URLSession.shared.page(from: job)
let newURLs = page.outgoingLinks.filter { url in
url.absoluteString.hasPrefix(basePrefix) && state[url] == nil
}
queue.formUnion(newURLs)
state[job] = page
}
}
}
18:52 Now we're getting more results, but the list has a lot of
duplicates. The crawler also takes a long time to finish, because it may be
stuck in a loop.
19:11 Before fixing these issues, we add an overlay to show the number
of crawled pages, which will tell us if the crawler is still running:
struct ContentView: View {
@StateObject var crawler = Crawler()
var body: some View {
List {
}
.overlay(
Text("\(crawler.state.count) items")
.padding()
.background(Color.black.opacity(0.8))
)
}
}
Removing Duplicates
20:30 There are multiple reasons why we're getting duplicate pages, one
of which has to do with how we construct a URL from an outgoing link. It's
possible that the initializer of relative URLs constructs different values for
different base URLs. Let's say we're fetching the /about page and it has a
link to /books. The URL we construct there might not be equal to the link to
/books we find on /blog, even though they point to the same books page in
the end. We can avoid these duplicates by converting all URLs to absolute ones:
extension URLSession {
func page(from url: URL) async throws -> Page {
let (data, _) = try await data(from: url)
let doc = try XMLDocument(data: data, options: .documentTidyHTML)
let title = try doc.nodes(forXPath: "//title").first?.stringValue
let links: [URL] = try doc.nodes(forXPath: "//a[@href]").compactMap { node in
guard let el = node as? XMLElement else { return nil }
guard let href = el.attribute(forName: "href")?.stringValue else { return nil }
return URL(string: href, relativeTo: url)?.absoluteURL
}
return Page(url: url, title: title ?? "", outgoingLinks: links)
}
}
21:33 We're also seeing many URLs with fragments. We can remove these
by stripping any suffix that starts with a # character:
extension URLSession {
func page(from url: URL) async throws -> Page {
let (data, _) = try await data(from: url)
let doc = try XMLDocument(data: data, options: .documentTidyHTML)
let title = try doc.nodes(forXPath: "//title").first?.stringValue
let links: [URL] = try doc.nodes(forXPath: "//a[@href]").compactMap { node in
guard let el = node as? XMLElement else { return nil }
guard let href = el.attribute(forName: "href")?.stringValue else { return nil }
return URL(string: href, relativeTo: url)?.simplified
}
return Page(url: url, title: title ?? "", outgoingLinks: links)
}
}
extension URL {
var simplified: URL {
var result = absoluteString
if let i = result.lastIndex(of: "#") {
result = String(result[..<i])
}
return URL(string: result)!
}
}
23:01 For some pages, both a URL with a trailing slash and one without
are listed. So we remove the trailing slashes from all URLs:
extension URL {
var simplified: URL {
var result = absoluteString
if let i = result.lastIndex(of: "#") {
result = String(result[..<i])
}
if result.last == "/" {
result.removeLast()
}
return URL(string: result)!
}
}
Coming Up
24:28 The crawler now finds all pages once, extracting titles and
outgoing links. But the crawl method loads just one page at a time. In the
next episode, we want to parallelize this process by running multiple child
tasks at the same time. Since these tasks will operate on the same queue, we'll
have to use actors to synchronize access to the queue. We'll also need task
groups to wait for all child tasks to be done.
