00:06 Today, we'll start working on a pure Swift implementation of a small
part of Git. Although there's a lot to Git, the actual underlying storage system
is quite simple — for sake of this project, we can reduce it to blobs, trees,
commits, and tags. Reimplementing this will be interesting because we'll deal
with a real project and handle binary data. And we'll also get to know more
about how Git works under the hood.
Inspecting a Repository
00:51 We can start by creating an actual Git repository with a single
file, and then we'll try to read that file using Swift. So, we create a new
subdirectory, sample-repo, and we create a file containing the phrase "Hello, world". Then, we initialize a Git repository in this directory by running git init:
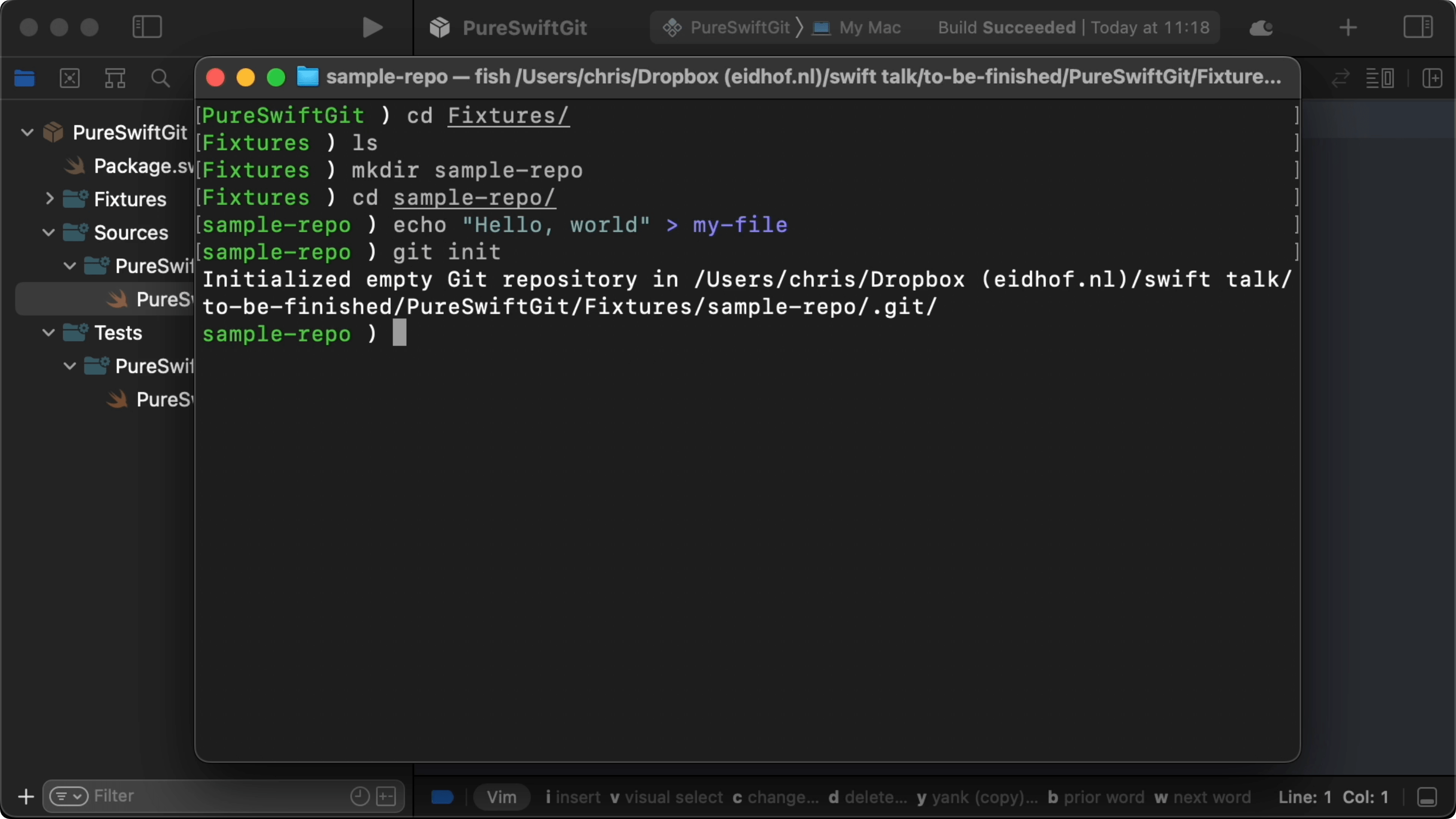
01:25 This creates the .git directory containing a config file, a few
empty directories, and a number of sample hooks. We can now add our file and
create our first commit. When we run find .git, we see that some things have
been added to the objects directory:
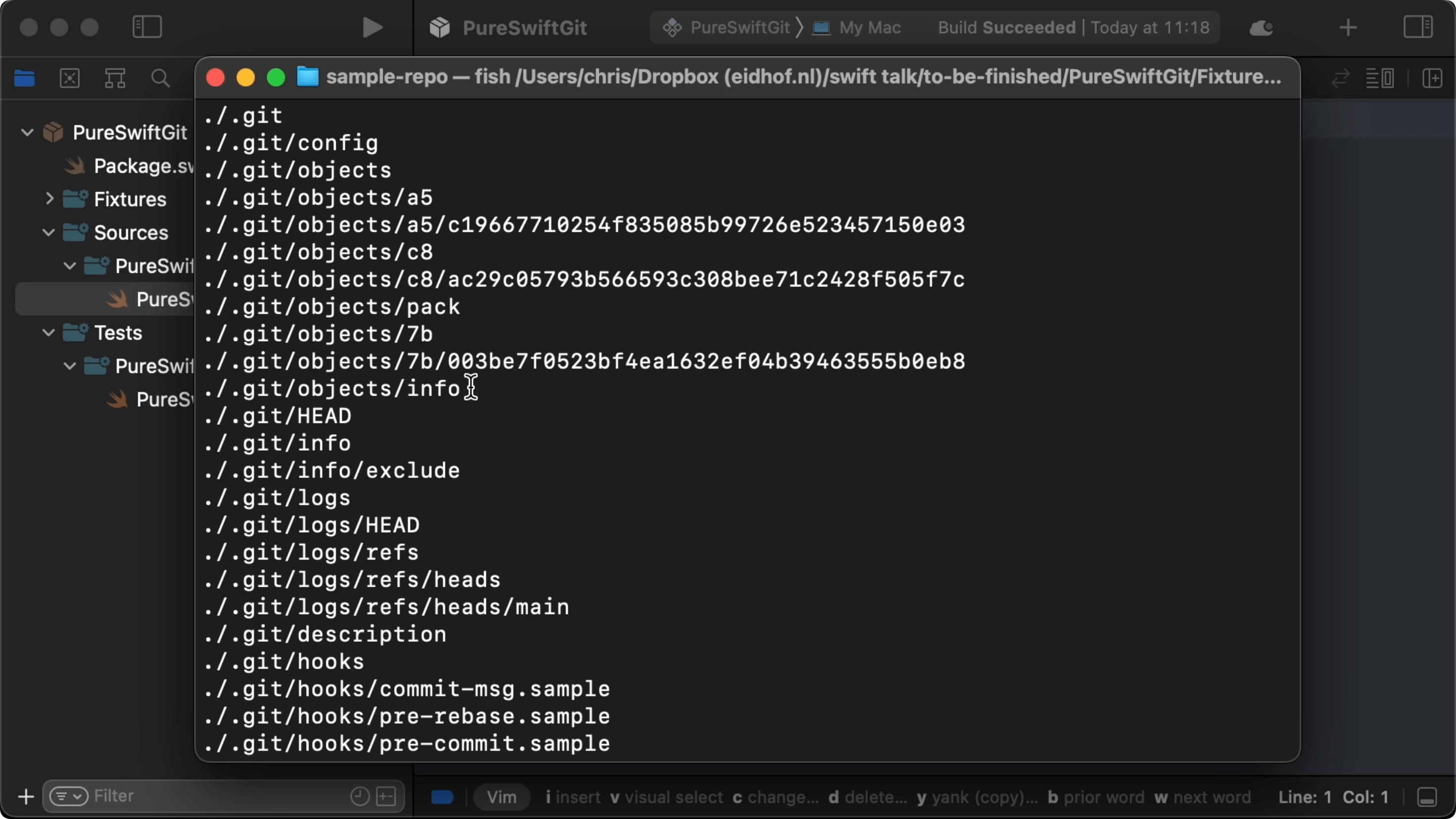
There are now three objects: a blob object containing the contents of the file,
a tree object containing the name of our file and a pointer to the contents
blob, and a commit object that contains a pointer to the tree. In short, the
commit points to the tree and the tree points to the contents.
02:48 We can have a quick look at each of these objects by running git cat-file with an object's hash. We get this hash by combining the two digits of
the directory name and the object's file name (the hash is split into these two
parts by Git to keep the objects directory organized):
git cat-file -p a5c19667710254f835085b99726e523457150e03
03:06 This outputs the contents we just wrote to the file:
Hello, world
03:14 The second object is the commit. It has a pointer to the tree,
along with the author, the committer, and the commit message:
tree 7b003be7f0523bf4ea1632ef04b39463555b0eb8
author Chris ...
committer Chris ...
First commit
03:36 The third object is the tree, and it contains a list of files:
100644 blob a5c19667710254f835085b99726e523457150e03 my-file
This list might also contain a pointer to another tree, constituting a
subdirectory. But in this case, there's just one blob, which is an actual file.
04:00 A commit typically also has a parent, since commits are built on
top of each other. What might be surprising to a lot of people is that there are
no diffs stored anywhere; we just have blobs and trees. Diffs we see in Git
clients, for example, are derived by comparing blobs.
Reading the Repository from Swift
04:32 Let's try to read this repository from Swift. The first thing we
need is a Repository struct. We initialize this struct with a URL so that we
have a container to work with:
public struct Repository {
var url: URL
init(_ url: URL) {
self.url = url
}
}
05:26 We can infer the Git directory from this URL, because this is
conventionally a subdirectory named .git:
public struct Repository {
var url: URL
init(_ url: URL) {
self.url = url
}
var gitURL: URL {
url.appendingPathComponent(".git")
}
}
06:08 Let's define how we want this to work by writing a test. The first
thing we need to do is read a blob. This requires a Repository, for which we
need the file URL of our test repo. By using the #file command, we can create
a URL that's relative to this Swift file:
final class PureSwiftGitTests: XCTestCase {
func testReadBlob() throws {
let fileURL = URL(fileURLWithPath: #file)
let repoURL = fileURL.deletingLastPathComponent().appendingPathComponent("../../Fixtures/sample-repo")
let repo = Repository(repoURL)
}
}
08:24 Now we want to be able to call a readObject method with a hash.
Let's pick the blob object's hash for this test:
final class PureSwiftGitTests: XCTestCase {
func testReadBlob() throws {
let fileURL = URL(fileURLWithPath: #file)
let repoURL = fileURL.deletingLastPathComponent().appendingPathComponent("../../Fixtures/sample-repo")
let repo = Repository(repoURL)
let obj = try repo.readObject("a5c19667710254f835085b99726e523457150e03")
}
}
09:01 We then need an assertion about the return object, but let's
create an Object type first. This type can be enum, because we know each of
its values will be one of three different kinds of objects:
enum Object {
case blob(Data)
case commit
case tree
}
09:50 In the readObject method, we receive a hash and we need to read
the contents of a file. First, we construct the path to the file by splitting
the hash into two parts — the first two characters, and the remainder. Then we
try to read the data:
public struct Repository {
func readObject(_ hash: String) throws -> Object {
let objectPath = "\(hash.prefix(2))/\(hash.dropFirst(2))"
let data = try Data(contentsOf: gitURL.appendingPathComponent("objects/\(objectPath)"))
}
}
11:38 Our aim isn't to have a secure implementation; if people put ..
in the hash, this might let us read other stuff in the file system. So we just
add a note that the received hash should be validated.
12:00 When we try decoding the read data into a string, we can see that
it doesn't work:
public struct Repository {
func readObject(_ hash: String) throws -> Object {
let objectPath = "\(hash.prefix(2))/\(hash.dropFirst(2))"
let data = try Data(contentsOf: gitURL.appendingPathComponent("objects/\(objectPath)"))
print(String(decoding: data, as: UTF8.self))
fatalError()
}
}
Decompressing
12:22 This is because the objects are all compressed using zlib. We have
a few episodes about async
sequences
and
streams,
in which we read and parsed XML in chunks, but rather than reimplementing that,
we're just going to take some decompression code with an MIT license from the
internet. This code is simple because it only decompresses data with a fixed
buffer size, which means it won't work with data larger than 8 MB, but that
won't be a problem in this particular project:
import Foundation
import Compression
extension Data {
var decompressed: Data {
let size = 8_000_000
let buffer = UnsafeMutablePointer<UInt8>.allocate(capacity: size)
defer { buffer.deallocate() }
let result = dropFirst(2).withUnsafeBytes({
let read = compression_decode_buffer(
buffer,
size,
$0.baseAddress!.bindMemory(
to: UInt8.self,
capacity: 1
),
$0.count,
nil,
COMPRESSION_ZLIB
)
return Data(bytes: buffer, count: read)
})
return result
}
}
14:03 We should now be able to append decompressed to the data and
then print our string:
let data = try Data(contentsOf: gitURL.appendingPathComponent("objects/\(objectPath)")).decompressed
14:13 If we run the test, we can see it prints blob 13Hello, world.
What we cannot see is that there's a zero byte between 13 and Hello. A blob
object always starts with the four letters blob, followed by a space, then the
size of the blob, the zero byte, and finally the data. The blob's size is
included to allow C programmers to allocate memory, but we can ignore it.
Parsing a Blob
15:51 We can use this pattern to parse the blob object. We assign the
data to a mutable remainder so that we can read and remove pieces from the
beginning of it:
var remainder = data
17:14 Then, we want to get the type string, i.e. blob or commit or
tree. We do this by taking the data's prefix up to the space character's byte,
i.e. 0x20:
remainder.prefix(while: { $0 != 0x20 })
17:53 To check the contents of the prefix, we decode it into a string:
let typeStr = String(decoding: remainder.prefix(while: { $0 != 0x20 }), as: UTF8.self)
18:26 When we print this string, we can see that we're getting the word
blob, so we're on the right track.
18:55 Next, we need to skip over the space and the blob's size. And
since we'll be doing this a lot — taking a prefix up until a certain point and
then removing it — we can extend Data with a helper method that does this.
This method takes a separator element, reads the prefix off the start of the
data, removes both the prefix and the separator from the data, and returns the
prefix:
extension Data {
mutating func remove(upTo separator: Element) -> Data {
let part = prefix(while: { $0 != separator })
removeFirst(part.count)
popFirst()
return part
}
}
22:05 We can now call the helper to parse the type string:
let typeStr = String(decoding: remainder.remove(upTo: 0x20), as: UTF8.self)
22:34 We then discard the blob size by removing everything up to the
zero byte:
remainder.remove(upTo: 0)
22:53 We've now reached the point of the blob where its data starts. We
switch over the type string to check if it is in fact a blob object, and if it
is, we return the .blob case with remainder as its associated value:
public struct Repository {
func readObject(_ hash: String) throws -> Object {
let objectPath = "\(hash.prefix(2))/\(hash.dropFirst(2))"
let data = try Data(contentsOf: gitURL.appendingPathComponent("objects/\(objectPath)"))
print(String(decoding: data, as: UTF8.self))
var remainder = data
let typeStr = String(decoding: remainder.remove(upTo: 0x20), as: UTF8.self)
remainder.remove(upTo: 0)
switch typeStr {
case "blob": return .blob(remainder)
default: fatalError()
}
}
}
23:53 To get rid of the compiler warning about not using the removed
blob size, we mark the remove(upTo) method as returning a discardable result.
And inside the method, we assign the result of popFirst() to an underscore to
make it explicit that we're not interested in the removed separator:
extension Data {
@discardableResult
mutating func remove(upTo separator: Element) -> Data {
let part = prefix(while: { $0 != separator })
removeFirst(part.count)
_ = popFirst()
return part
}
}
24:11 We can now write our assertion about the read object. To compare
the result and the expected object, we need to make Object equatable. We do so
by conforming it to Hashable, which inherits Equatable:
enum Object: Hashable {
case blob(Data)
case commit
case tree
}
24:44 We construct the object we expect to read, and we compare the
actual result to it:
final class PureSwiftGitTests: XCTestCase {
func testReadBlob() throws {
let fileURL = URL(fileURLWithPath: #file)
let repoURL = fileURL.deletingLastPathComponent().appendingPathComponent("../../Fixtures/sample-repo")
let repo = Repository(repoURL)
let obj = try repo.readObject("a5c19667710254f835085b99726e523457150e03")
let expected = Object.blob("Hello, world".data(using: .utf8)!)
XCTAssertEqual(obj, expected)
}
}
25:12 The test fails because there's a difference of one byte. This is
because of the newline character appended to the file's contents (from using
echo). After we adjust our expectation, the test passes:
let expected = Object.blob("Hello, world\n".data(using: .utf8)!)
25:30 In summary, we can now get into a repository and read a blob
object from it. We do this by unzipping and parsing the blob. These are by far
the easiest objects, but trees and commits should also not be very hard. Let's
continue with those next time.
